What is a Dependency Gradient?
This is a follow-on to 6BI and Aggregate-Orientation, an article published on this blog in 2017 which can be found at https://birkdalecomputing.com/6bi-home/6bi-and-aggregate-orientation/.
In large data models built around the concept of entity types and their relationships to one another, one often finds dependencies that span across several entities. As entities link to more and more other entities the relationships built on these links typically begin to form webs of dependency. Many of these links represent dependencies where an occurrence of one entity depends on the occurrence of another. These dependencies can range from direct links between two entities without any other entity intervening, to relationships between entities where there are multiple entities between the end points. The dependencies between these entity types can be measured and graphed as a gradient.
There are several different types of gradients used in different areas of study. Types of gradients and the fields in which you find them include:
- Gradual change in color (color theory)
- Incline of a hill (engineering)
- Slope of a curve (math, especially calculus)
- Difference in concentration of a biological substance (molecular biology)
Respectively these gradients measure: (1) the small gradual difference in color on a color wheel, (2) how the incline of a hill increases with distance, (3) the descent along a bowl shaped area on a graph (this has great relevance to machine learning in that gradient descent is a major methodology to evaluate the effectiveness of some classes of ML algorithms), and (4) the difference in concentration of protons on one side of the intra-cellular membrane of mitochondria, through which electromechanical charge passes during cell respiration.
A gradient is the differential concentration of some substance between one place in a system and another place in the same system. The granularity of a gradient can be anything from microscopic to the size of a mountain. As long as the concentrations being compared are contiguous and exhibit either a smooth or ratcheted flow of the substance being observed, we have a gradient.
A Dependency Gradient (DG) is a continuous change in the concentration of dependency that is present in a data model between one area of the model and another. It is measured by the concentration of links (relationships) between entities in the data model, or by the concentration of edges between nodes in a graph model. One of the main differences between a data model and a graph model is that a data model is specifically designed to model data, while a graph model can model phenomena that we don’t think of right away as data. When stored on a computer, however, both type model data.
It should also be noted that the relationships between entities (or nodes) may also exist outside the model itself and be borne by the processes that use the data. These extra-model relationships are by their nature dynamic. They can potentially have little or no latency. They also can have little or no persistence in that once an action takes place, the relationships between its data go away. There can be relationships within a model that are not realized in the metadata of the model, but only become apparent once there is content data created and structured in the shape of the model. These relationships are realized only through the use of the data. They are often ethereal and do not survive past a use session. Nevertheless, these relationships often indicate data dependencies can recur over and over again as the data is used and yet never be captured in the metadata of the design.
My background is in data modeling, so the example that follows will use data modeling techniques to show what a Dependency Gradient is.
Data models are made up of some number of binary links that specifically represent some form of existential or fulfillment relationship that a dependent entity type has on an independent entity type. The terms “dependent” and “independent” refer only to the role that an entity type plays in the relationship, not to some universal property of the entity. An entity type can be dependent in one relationship and independent in another.
Figure 1 shows a set of binary links between a dependent entity (Order_Payment) and the independent entities with which it has fulfillment dependencies, (Customer) and (Payment). This creates two Dependency Gradients: Dependency Gradient 1, flowing from left to right in the diagram, and Dependency Gradient 2, flowing from right to left. DG1 is a direct relationship (one link), it has no intermediate entities. DG2 is an indirect relationship (three links), there are two intermediate entities, Order_Invoice and Order. The concentration of dependency (i.e., the substance of the gradient) is 100% on the dependent ends (which just happen to be the same entity in this example, but need not be) and 0% on the independent ends.
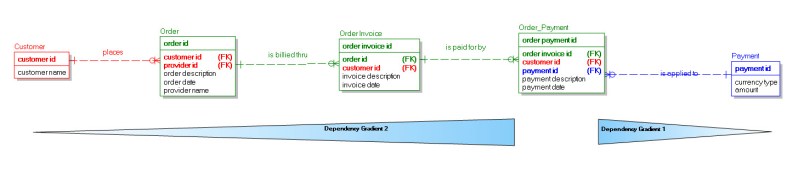
Figure 1.
The more intermediate entities there are between a dependent entity and an independent entity in a model, the greater the Dependency Gradient. In other words, the more distance there is between the leaf node[i] of a dependency path and the apex node[ii] of that path, the greater the DG.
The higher the DG of a model (data or graph) the more difficult it will be to change the model to meet changing circumstances. When you include dynamic dependencies generated from content data flowing into and out of a database such as an RDBMS or a DDBMS the complexities created by Dependency Gradients can increase greatly.
Ideally the Dependency Gradient of a model should be able to be measured by counting the links and dependency paths that make up its dependency tree. This consists of the links in the unique paths between all leaf node dependent entity types, and all apex node independent entity types. The higher the number of links is one measure, the number of dependency paths is a second measure, and the number of times an entity participates in a dependency path is a third measure. Together these measures can give you a good idea of the internal dependency concentration in a model. The amount of dependency in a data model, gradaph model, or document model can determine its fragility and its adaptability to changing circumstances. The higher the Dependency Gradient in any given model the less adaptable it will be and the higher the cost will be to change it to meet changing business needs.
[i] Called a “base entity” in the previous article.
[ii] Called an “apex entity” in the previous article.
