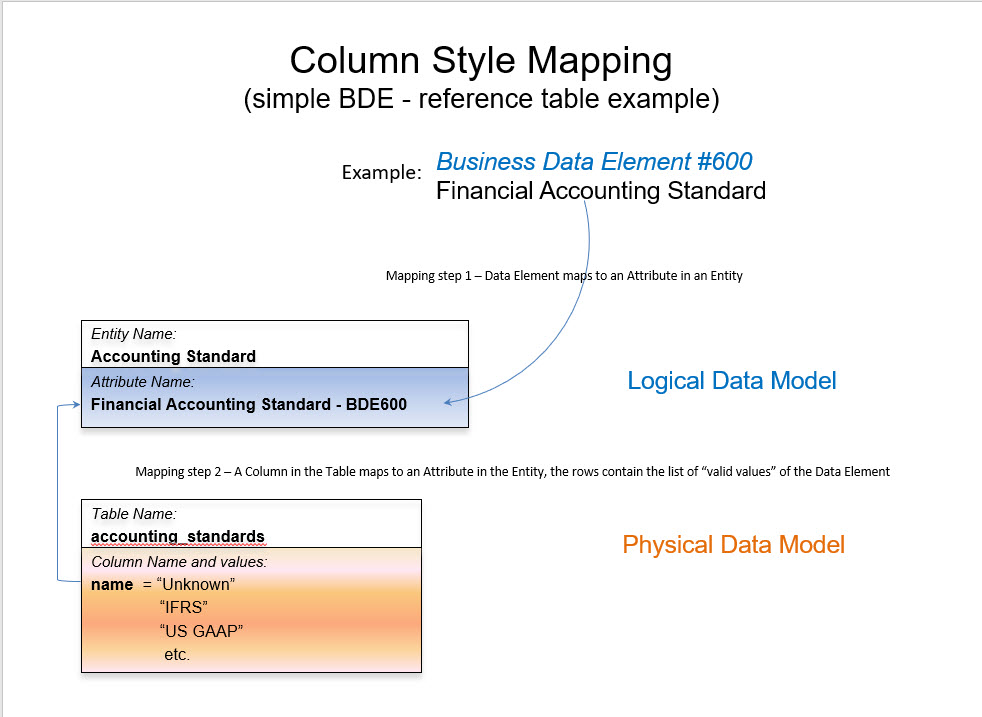
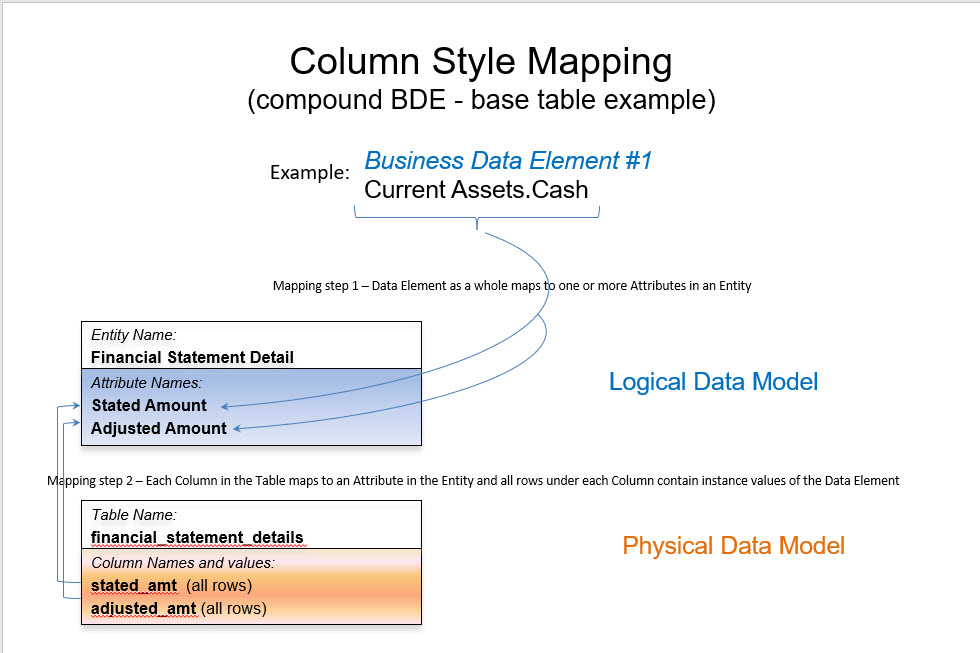
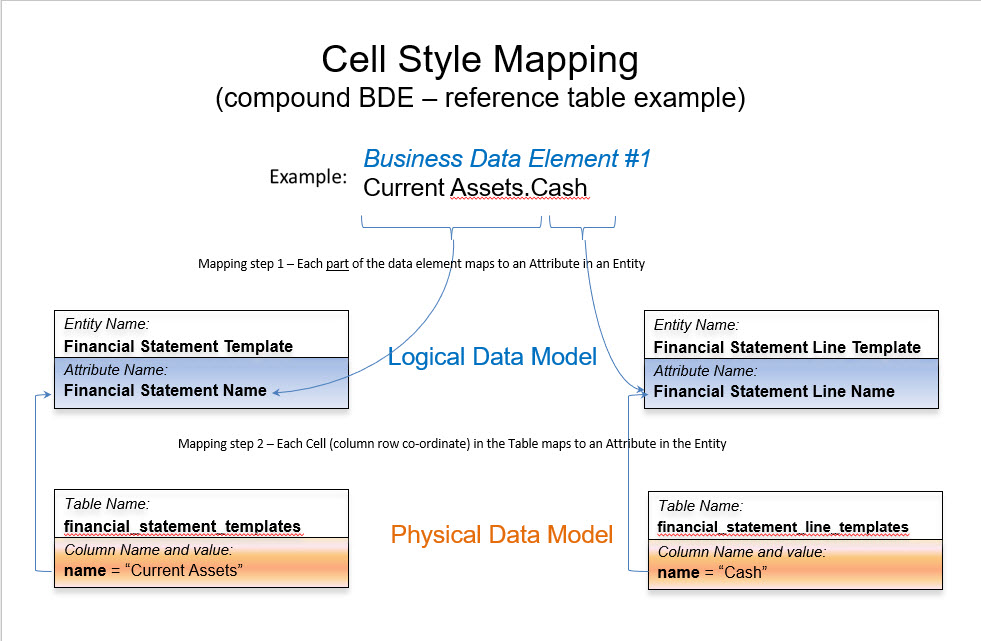
Six Basic Interrogatives (BI) can be used to analyze marketing attribution. In marketing, attribution is the assigning of credit to the interactions in the sequence of interactions which have led up to what is called a conversion[i]. A conversion is an action, or event which results in an action, that has value for the means of interaction, the campaign, which is seen to be the motivator of the visitor’s interactions and eventual conversion. The interactions take place through channels which when associated with a campaign are called touchpoints.
To pursue the most effective marketing strategy it is important to know which touchpoints, and in what sequences they occur, are the most likely to result in conversions. A typical scoring system to assess these sequences of actions consists of assigning credit to the touchpoints in a sequence according to some attribution rule or rules. There are several popular attribution rules in use across the field of marketing analytics. These rules fall into three broad categories.[ii]
- Single Source Attribution (Single Touch Interaction) models assign all the credit to one event, such as the last click, the first click or the last channel to show an ad. Simple or last-click attribution is widely considered as less accurate than alternative forms of attribution as it fails to account for all contributing factors that led to a desired outcome.
- Fractional Attribution (Multi-Touch Interaction) includes equal weights, customer credit, and multi-touch / curve models. Equal weight models give the same amount of credit to all events, customer credit uses past experience and sometimes simply guesswork to allocate credit. Multi-touch assigns various credit across all the touchpoints in set amounts.
- Algorithmic Attribution uses statistical modeling and machine learning techniques to derive probability of conversion across all marketing touchpoints which can then be used to weight the value of each touchpoint preceding the conversion. Algorithmic attribution analyzes both converting and non-converting paths across all channels to determine probability of conversion. With a probability assigned to each touchpoint, the touchpoint weights can be aggregated by a dimension of that touchpoint (channel, campaign, interaction placement, visitor type, content type, etc.) to determine a total weight for that dimension.
Examples of each category of attribution model include the following:
Single Source Attribution[iii]
- The Last Interaction model attributes 100% of the conversion value to the last channel with which the customer (or visitor) interacted before buying or converting.
- The Last Non-Direct Click model ignores direct traffic and attributes 100% of the conversion value to the last channel that the customer clicked through from before buying or converting. Google Analytics uses this model by default when attributing conversion value in non-Multi-Channel Funnels reports.
- The Last AdWords Click model attributes 100% of the conversion value to the most recent AdWords ad that the customer clicked before buying or converting.
- The First Interaction model attributes 100% of the conversion value to the first channel with which the customer interacted.
Fractional Attribution[iii]
- The Linear model gives equal credit to each channel interaction on the way to conversion.
- The Time Decay model may be appropriate if the conversion cycle involves only a short consideration phase. This model is based on the concept of exponential decay and most heavily credits the touchpoints that occurred nearest to the time of conversion. The Time Decay model could have half-life of 7 days, meaning that a touchpoint occurring 7 days prior to a conversion will receive 1/2 the credit of a touchpoint that occurs on the day of conversion. Similarly, a touchpoint occurring 14 days prior will receive 1/4 the credit of a day-of-conversion touchpoint.
- The Position Based model allows you to create a hybrid of the Last Interaction and First Interaction models. Instead of giving all the credit to either the first or last interaction, you can split the credit between them. One common scenario is to assign 40% credit each to the first interaction and last interaction, and assign 20% credit to the interactions in the middle.
Algorithmic Attribution[iv]
Algorithmic attribution is a more advanced way to model attribution data in order to most accurately represent the visitor interaction event flow. Algorithms tend to be proprietary so what factors are considered in the algorithm and what weight each factor gets can vary by attribution provider. However, the most accurate algorithmic attribution models use machine learning to intake vast amounts of data, all of the touchpoints, both historical and going forward, that went into closed-won deals, closed-lost deals, deals that fell apart at or before the opportunity stage, etc. to create enterprise specific models.
The algorithm then creates custom weights for each of your stages to represent how your visitors go through the funnel. It’s important to note that it should also use new data as you continue to engage prospects and close deals to refine and improve the model, which is the machine learning aspect.
The 6BI Analytics Schema in Figure 1 lays out the fundamental base entities that support marketing attribution. This diagram also enumerates the process by which business value is extracted from that schema. Keep in mind this is a high level logical data model (LDM) and certainly not intended to be sufficient for generating database tables without far more domain specific modeling.
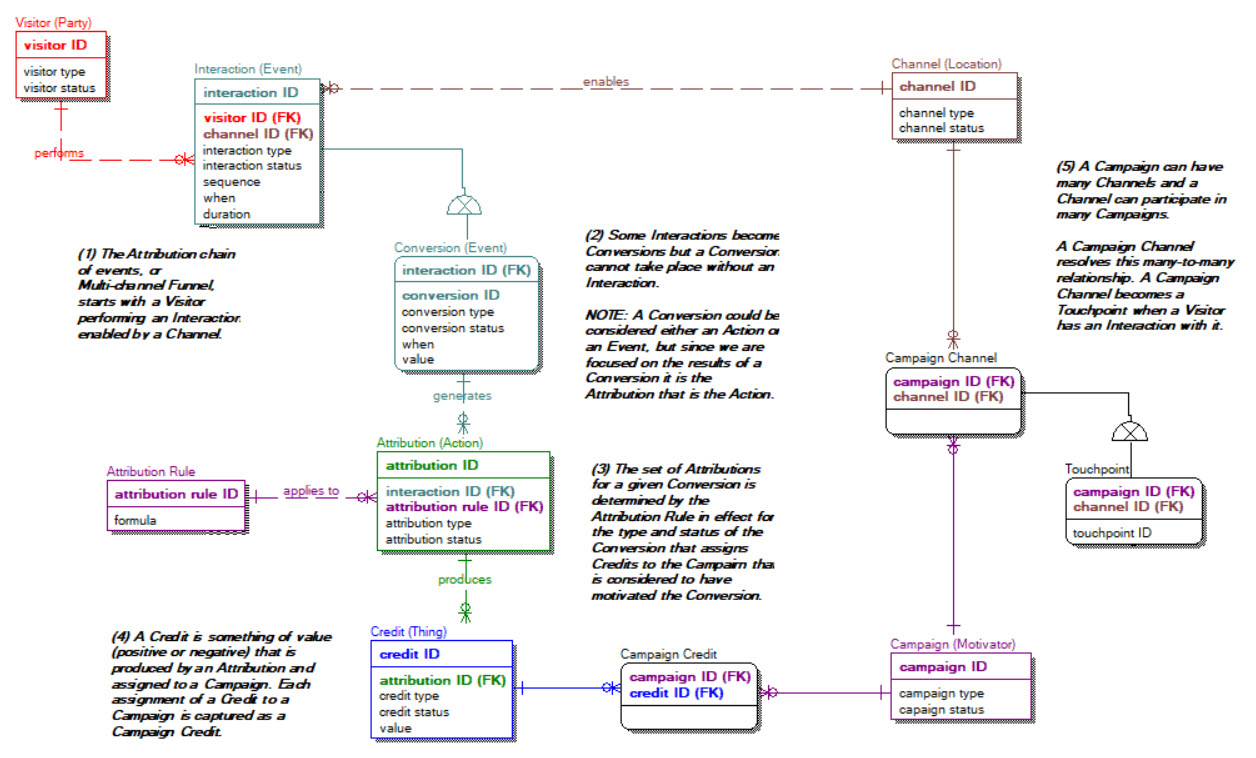 Figure 1.
Figure 1.
From a 6BI perspective the Visitor is a type of Party because it represents “who” initiates the sequence of events. Interaction and its sub-type Conversion are types of Events, they identify “when” an action takes place. Credit, a type of Thing, more specifically a Thing of Value to the campaign is “what” the action produces. Attribution, a type of Action, is “how” a credit is produced. The Channel, a type of Location is “where” the events occurred. The assumption as to “why” the visitor interacts and converts is due to the influence of a Campaign, which is a type of Motivator.
The assigning of Campaign Credits to Campaign Channels is identified in Figure 1 by a series of five (5) steps. This process begins with a Visitor performing a type of Interaction, through a Channel, which causes it, the Interaction, to become a Conversion. The Conversion generates Attributions which, based on the application of an Attribution Rule produce Credits which are assigned to a Campaign. The use of a Channel by a Campaign identifies the Touchpoints which ultimately get evaluated based on how much Credit they produce for the Campaign.
To get the net benefit of attribution you need to capture the cost side as well. You need to know and use, in your assessments, not only the costs of applying the attribution rules, but the costs of channels, touchpoints, impressions and campaigns as well. Not only do you need to determine how much influence, for example, your Paid Search feed had in generating conversions when it was the second touchpoint, but the cost of the Paid Search feed service to your enterprise as whole.[v]
The goal of attribution is to determine which touchpoints are producing a positive result, and, by using the cost of each touchpoint, an attribution system can then show which touchpoints are profitable. This allows optimization of marketing expenditures.[vi]
[i] Conversion is a generalized term for the desired result of a marketing effort. This can include other actions besides sales such as sign-ups, survey completions, favorable ratings, etc.
[ii] https://en.wikipedia.org/wiki/Attribution_(marketing)
[iii] https://support.google.com/analytics/answer/
[iv] https://www.bizible.com/
[v] The cost of a touchpoint might vary depending on whether it is first, last or some intermediate (assisting) interaction in the conversion event flow.
[vi] https://www.convertro.com/