This article was first published August 1, 2010 on The Data Administration Newsletter (TDAN) website but is no longer available there. It is the first of a two-part series presenting a simple model for capturing the structure of the “why” aspect of the Zachman Framework.
In this article about the data architecture of business plans we will look at a standard meta-model for modeling business motivation. From an enterprise architecture prospective a business plan is the type of artifact produced at the intersection of the Business Model perspective (row two) and the Motivation aspect (column six) of the Zachman Framework, one of the most widely recognized and referenced frameworks for enterprise architecture [i]. Since models of business motivation are of most importance to business owners, this perspective is also referred to as the Business Owner perspective and the corresponding standard meta-model as the Business Motivation Model[ii].
We will explore how the standard meta-model can be extended to support the data architecture of key performance indicators (KPIs) which are popular assessors of the measurements of business performance. These measurements are often assessed in reference to the goals and objectives of the enterprise. KPIs are widely used tools in enterprise performance management (EPM) scorecards, which are in turn ubiquitous components of all three types of performance dashboards: Strategic, Tactical and Operational[iii].
The Motivation aspect addresses the question of why certain courses of action are chosen or should be chosen, why certain types of persons and organizations are important, why certain products should be more heavily invested in and why corrective actions need to be taken for others, why certain events are important, and why some locations are preferred over others. We will take a look at the structure of the data that describe the Motivation aspect of the enterprise from the perspective of the Business Owner. The data we will model in this article describe the entities and relationships of the data content that describes the “real world” motivations of an enterprise and thus we refer to it as metadata and the models used to understand it as meta-models.
From a Six Basic Interrogatives or 6BI[iv] point of view, when we are creating or vetting the design of a software application intended to support decision making, we seek answers to questions that will tell us “why” our client makes or should make certain business decisions and not others and “why” it is worth making the investment necessary to build (or buy) the solution we are proposing and not take another course of action. These “why” questions are just as important to ask as questions such as “what” information do we need to make the application a reality; “who” will use the application, and “how” do we measure our success.
Business Motivation Modeling
There are three business architecture models that address the Motivation aspect of the Business Owner’s perspective of an enterprise. These models are high level views that do not depend on any particular technology. In developing an enterprise performance management solution we will usually begin with one or more of the following business motivation models:
- Business Goals Hierarchy (BGH)
- Business Opportunities Hierarchy (BOH)
- Business Problems Hierarchy (BPH)
These are business architecture models designed to show details of the business vision and strategy of an enterprise. In practice the level-of-detail will vary with the scope of the engagement. If we are engaged at the top executive level then the scope is enterprise-wide. If we are engaged at the departmental or business unit level of an organization then the level-of-detail will need to be aligned with the scope of the sponsoring department or business unit in order to deliver value to the client. The scope of the goals, opportunities or problems determines the scope of the strategy. There are no well defined, hard and fast criteria for differentiating one level-of-detail from another. The levels are there as guidance to help us think more architecturally about the aspects of the business of an enterprise.
Each model depicts, in a hierarchical fashion, a different type of motivator. Each of the business motivation models is composed of a hierarchical set of “is a kind of” relationships. One approach is to start at the top with what is sometimes referred to as the apex motivator of the organization. For example, what is the organization’s single most important goal. This is most often a financial goal, but with the emerging interest in sustainability and the “triple bottom-line” may now incorporate environmental and social objectives as well.
In each model, the types of motivators depicted become more specific, finer grained, and less abstract as one progresses down the hierarchy, until reaching the “leaf node” of each branch. Another approach is to start as close to the leaf level as possible and to progress up, across and down the hierarchy all at more or less the same time. Many business analysts advocate, for reasons we need not discuss here, that this is the only practical way to actually make progress in a constrained time frame. In either case a hierarchy of motivators is created.
The apex business goal is the highest level, most abstract and most all-encompassing of all the business goals in the subject area of the BGH (Business Goals Hierarchy). The apex business opportunity is the highest level business opportunity in the BOH (Business Opportunities Hierarchy) and similarly with the Business Problems Hierarchy (BPH).
Though the three models, BGH, BOH and BPH, have virtually identical structures, goals tend to be more strategic in nature, while opportunities and problems, which are more immediate in nature, tend to be more tactical or operational. In this article we will use the Business Goals Hierarchy to illustrate the concepts behind the data architecture of business plans.
Core Business Plan Elements
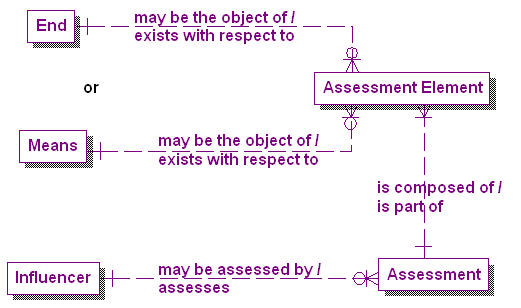
Figure 1 presents the core elements of the meta-model for business plans. Business motivation is fundamentally about four things: Ends, Means, Influencers, and Assessments. Anecdotally, Ends are where we want to get, Means are how we get there, Influencers are people, processes and technology that can influence getting there, and Assessments are how we measure if we got there.
Figure 1. Core elements of the Business Plans meta-model.

Correspondingly, in our meta-model, an End is something that an enterprise sets out to accomplish. A Means is any capability that can be called on, activated, or enforced by the enterprise to achieve an End [v]. An Influencer is anything that can produce an effect on the enterprise without apparent exertion of tangible force or direct exercise of command[vi]. The effect of Influencers on Means and Ends is determined by one or more Assessments. An Assessment is a judgment about the implications of the Influencer either with respect to one or more Means or with respect to one or more Ends. Since an Assessment can have multiple implications, each Assessment must be composed of one or more Assessment Elements. Each of these Assessment Elements then must exist with respect to either one Means or one End [vii].
In other words, the metadata describing the data architecture of business plans also describes a re-useable template for building data models to analyze, compare and improve those plans. Architecturally business plans must include data elements that represent the answers to the basic interrogatives that the plans are created to address. These basic interrogatives will include: “What is the objective that is intended to be accomplished?” – the End; “How does the process work that will get the end accomplished?” – the Means; “Who are the people and organizations that influence the process?” and “What are the technologies and other processes that will get it accomplished?” – the Influencers; and, “When was or will it be accomplished, and “How closely to expectations did it turn out to be?” – the Assessments. These are the meta-dimensions[viii] of the problem space.
Data elements that support the “When” interrogative, though not explicit in Figure 1, are very important as well, because we can accomplish our Ends through our planned Means, taking advantage of the appropriate Influencers and still fail our Assessment because the goals were not accomplished on a timely basis.
Ends
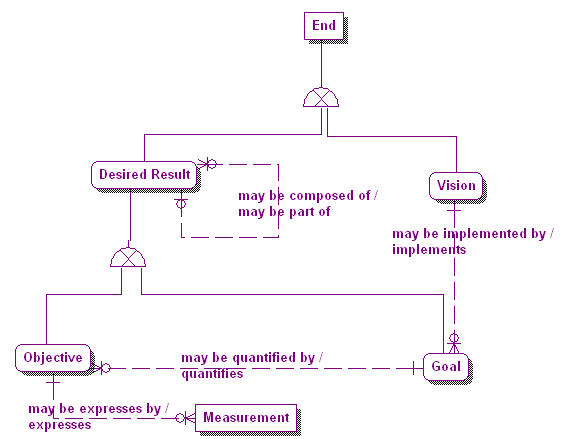
Figure 2 expands the business plans meta-model into two types of End: the Vision, which is the primary End that the enterprise sets out to accomplish, and the Desired Result, which is a state or target the enterprise intends to maintain[ix].
There are two types of Desired Result: Goals and Objectives. A Goal is a Desired Result that is a specific statement about a state or condition of the enterprise to be brought about or sustained through appropriate Means[x]. A Goal is an implementer of a Vision. That is, where a Vision describes a future state of the enterprise in general, Goals define the steps to be taken to accomplish that Vision. A Goal, by definition, is more narrow than a Vision. A Vision is a broader or grander end state and cannot be specifically measured by Objectives, as a Goal can.
Figure 2. The Ends subject area in the Business Plans meta-model.
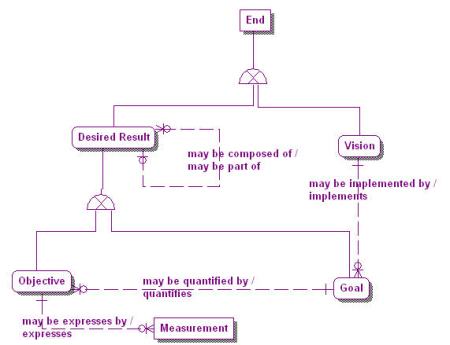
An Objective, on the other hand, is a statement of an attainable time-targeted and measurable Desired Result that the enterprise seeks to meet in order to directly achieve its Goals and through these, its Vision[xi]. An Objective, since it is measureable, quantifies a Goal. A Goal can be quantified by one or more Objectives, but an Objective can measure one and only one Goal. A Measurement is a specific value expressing one state of an Objective. An Objective can be expressed, usually serially over time, by one or more Measurements, but a Measurement expresses one and only one Objective.
Note from Figure 2 that a Desired Result can be composed of other Desired Results, thus creating a hierarchical structure. Since Goals and Objectives are types of Desired Result, they too can have a hierarchical structure[xii]. This is the basis for the hierarchical structure of business goals in the Business Goals Hierarchy where higher level goal instances are composed of successively lower level goal instances until we reach the leaf level of atomic goals. It should be noted that Measurements can be associated with any level of Objective and through this to any level in the hierarchy.
Business Goals Hierarchy
The Business Goals Hierarchy in Figure 3 describes Goals which the enterprise must achieve in order to accomplish its Vision. In the BGH, Goals and Measurements are shown in the same model. Typically Goals are depicted as orange “corner clipped” rectangles, and Measurements are depicted in the same model as yellow “corner clipped” rectangles[xiii].
Figure 3. A Business Goals Hierarchy (BGH).

The fact that a Measurement measures one and only one Goal is an important quality control factor and provides a clear assessment vehicle for performance indicators, as we will see. If a single Measurement is allowed to express more than one Objective and thus more than one Goal, there is no way to unambiguously trace a performance indicator using that Measurement back to the Vision of the enterprise and thus determine if it is a “key” performance indicator or not.
Of the three business motivation models (BGH, BOH and BPH) it is often advisable to start with the BGH first. Identifying a set of business goals as the first deliverable of a workshop establishes the scope early in the process and helps assure that the client receives value for their investment from the start by identifying the Ends that the client wishes to accomplish. It is the purpose of the BGH to capture and organize the Goals that will implement these Ends. However it is critically important that the goals be attainable, that measurable Objectives be set for them, and that they are vetted by the organization. There is sometimes the temptation to get the BGH over with quickly and get on with more tangible elements, but this would be a mistake. The BGH helps us to stay on track and solve the right problems for the enterprise. As other artifacts are developed it is always useful to go back to the BGH and ask yourself “Does what I am doing now help to accomplish the business goals?”
Starting with the BGH can mean either discovering the business goals, through interviews, documents, or other information gathering methods, separately or in combination. Or it could mean recording Goals that the enterprise has already identified and organizing them hierarchically.
One challenge in this process is getting participants to think “hierarchically” about business goals. Quite often business goals are not tied together in people’s minds nor in documentation in such a way that they easily roll up to higher level business goals or roll down to lower level business goals. Also, quite often business goals and objectives are not differentiated. In order to facilitate an architectural approach to business we need to often disambiguate terms that are used interchangeably. Business goals and objectives are examples of terms that need to be disambiguated in order to produce clear and executable business plans.
Means
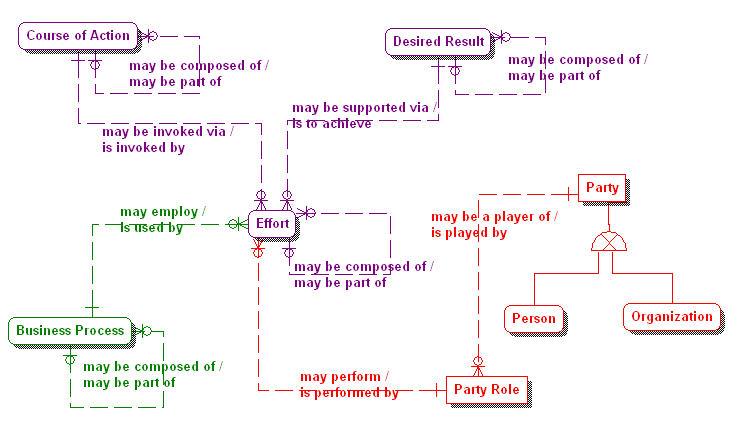
There are three types of Means depicted in Figure 4, another portion of the business plans meta-model. There is the Mission which is the primary Means by which the enterprise plans to make its Vision operative; the Course of Action which is an approach or plan for configuring some aspect of the enterprise; and the Directive which is a specification that governs or constrains a Course of Action[xiv].
Figure 4. The Means subject area in the Business Plans meta-model.

A Course of Action must be either a Strategy or a Tactic[xv]. A Strategy is the essential Course of Action attempted to carry out an enterprise’s Mission. The enterprise Mission, being the ultimate Means, can sometimes, though rarely, be carried out by more than one Strategy, especially for enterprises as vast as national governments or international corporations. For that same reason it is impossible for a Strategy to carry out more than one Mission[xvi]. A Tactic is a Course of Action that implements a Strategy by representing one or more details of that Strategy[xvii]. A Strategy can be implemented by one or more Tactics, but a Tactic is the implementer of one and only one Strategy.
A Course of Action can be composed of one or more other Courses of Action. However this compositional parent-child relationship does not cross Course of Action types. In other words, one Strategy may be a part of another Strategy, and one Tactic may be a part of another Tactic. But Tactics are separate element types from Strategies, they are implementers of Strategy, not parts of a Strategy.
The third type of Means, the Directive must be either a Business Policy or a Business Rule. A Business Policy is a non-actionable Directive that guides the activities of the enterprise or governs them in a general way. It “governs”, it does not control or shape Courses of Action[xviii]. A Business Rule is a more specific and actionable constraint on the enterprise. In particular, based on a Business Policy, it imposes a constraint on a fact or fact type[xix]. A complete look at business policies and rules includes elements that describe enforcement levels, implementations of the enforcement levels, invocations of the consequences that are the result of the enforcement level implementations, and how enforcement levels and consequences are affected by tactics. All of which are outside the scope of this article.
A Course of Action can also enable one or more other Courses of Action. Enabling is not the same as implementing. For example, a tactical Course of Action of an enterprise might be “Provide unified communication capabilities (i.e. integrated voice, email, instant messaging and video conferencing) to all employees”. This Tactic may enable the Tactic “Reduce intra-company communication delays”, which may in turn enable the Strategy “Improve company responsiveness”. Figure 5 shows the meta-model of this relationship. In it, the element Enablement implements a composite relationship between two Courses of Action. One Course of Action is the enabler of the relationship, while the other Course of Action is enabled by the relationship.
Figure 5. Enablement of Courses of Action.

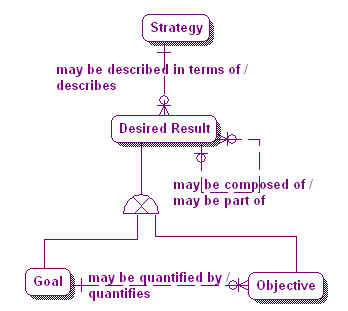
Strategies and Goals
The link between an enterprise’s Ends and Means is characterized as the relationship between its Vision and Mission. A Vision may be made operative by one or more Missions, and a Mission makes operative one and only one Vision[xx]. However most business planning activity takes place at the strategic level rather than at the mission level. In making strategic decisions, an enterprise’s mission is often considered a constant set of values that the strategy must carry out. With this in mind it makes sense to model the relationship between a Strategy, which is a type of Course of Action, and the Desired Results that describe it. Figure 6 illustrates this relationship. In it a Strategy may be described in terms of one or more Desired Results, each of which is either a Goal or an Objective.
Figure 6. Strategies and Desired Results.

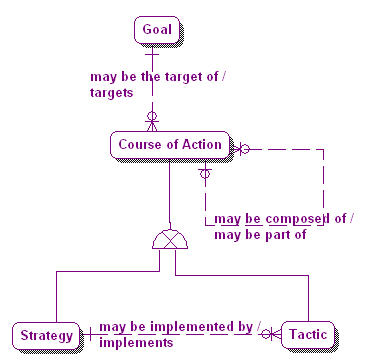
On the other hand a Goal, which is a type of Desired Result, may be the target of one or more Courses of Action, each of which is either a Strategy or a Tactic. This relationship is illustrated in Figure 7.
Figure 7. Goals and Courses of Action.

The basic takeaway here is that Courses of Action can be traced directly back to the Desired Results that motivate them.
Influencers and Assessments
To fully understand the meta-model of the data architecture of business plans it is necessary to understand not just its Ends and Means, but also with the real world things that influence them. These we call Influencers, where an Influencer is anything that can produce an effect on the enterprise without apparent exertion of tangible force or direct exercise of command[xxi].
The effect of Influencers on Ends and Means is determined by one or more Assessments, where an Assessment is a judgment about the implications of the Influencer either with respect to one or more Means (such as a particular Course of Action) or with respect to one or more Ends (such as a particular Desired Result)[xxii].
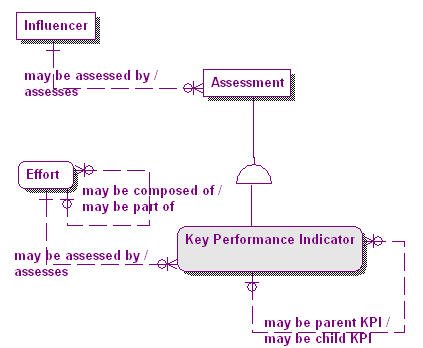
Figure 8 shows that portion of the meta-model that represents Influencers and Assessments. We can see that an Influencer is an example of one and only one Influencer Type. These types can be as basic as “Internal Influencer” and “External Influencer”, which tell us very little about this element, or all the way to a full taxonomy of Influencer Types, which can include all aspects of an enterprise. Influencer Types can also be nested in a supertype-subtype generalization hierarchy. A full analysis of influencers is well beyond the scope of this article. We also see that while an Assessment assesses one and only one Influencer, each Assessment must be composed of one or more Assessment Elements. Each Assessment Element, as was observed earlier, in Figure 1, must exist with respect to either one Means or one End.
Figure 8. Influencers and Assessments.

It is the Assessment Element and the fact that it may be revealed by one or more Potential Impacts on the enterprise that is the basis for the Key Performance Indicator (KPI). Figure 9 introduces the KPI into the meta-model as a type of Assessment. Because a KPI can be composed of other KPIs it has a reflexive parent-child relationship with itself. Each Assessment has its own types of Assessment Elements. Frequently encountered Assessment Elements include those used in “SWOT” analysis, such as Strengths, Weaknesses, Opportunities and Threats.
Every KPI must have at least three Assessment Elements. Target Expression, Actual Expression, and Status Expression are each a mandatory part of a KPI. In addition it can have other Assessment Elements which are optional. We will discuss these and other aspects of the data architecture and meta-model of KPIs in the second part of this article.
Figure 9. Assessments and KPIs.

Conclusion
The data architecture of business plans, also known as the Business Motivation Model, is important because it can be used to trace the results produced by Assessment Elements like Key Performance Indicators back all the way to the core motivational elements of an enterprise, its Ends and its Means. If the chain of traceable associations from Assessments like KPIs is unbroken, it is possible to architecturally trace back to the Desired Results that motivate an enterprise’s Courses of Action to understand the rationale for the Measurements used in the Assessment Elements of Key Performance Indicators that provide the most relevant picture of an enterprise’s performance. A refrain often heard in EPM projects is “Are we measuring the things that really matter?” “What are the things that will make the most difference to the enterprise?” With this two part article we will show that you can verify and validate these important associations through traceability all the way to the enterprise’s Ends and Means. In the second part of the article we will discuss how KPIs, Scorecards and Dashboards tie these elements together.
[i] I am referring to the co-ordinates of the Zachman Framework for Enterprise Architecture, first discussed in 1987, and extended in “Extending and Formalizing the Framework for Information Systems Architecture”, J.F. Sowa and J. A. Zachman, IBM Systems Journal, vol. 31, no. 3, 1992. IBM Publication G321-5488. For more on the Zachman Framework please refer to the website http://www.zifa.com/ .
[ii] Concepts in this article are based on the publications: “The Business Motivation Model, Business Governance in a Volatile World”, The Business Rules Group, Copyright 2007, The Business Rules Group, For more information refer to http://www.BusinessRulesGroup.org. This publication has since been replaced by the “Business Motivation Model, Version 1.0” published in August 2008 by the Object Management Group (OMG). For more refer to http://www.omg.org/ .
[v] Data Model Patterns: A Metadata Map, David C. Hay, The Morgan Kaufmann Series in Data Management Systems, Morgan Kaufmann, 2006. Page 277.
[viii] Please forgive me for introducing yet another term into our ever growing business and IT vocabularies, but the metamodel of a dimensional database design would contain “meta-dimensions”, would it not?
[xii] In object oriented terminology we would say that “Goal” is a sub-type of “Desired Result” and inherits its properties, including its relationships. In this case the relationship is an aggregation, or “part of “ relationship, with itself, creating a reflexive relationship.
[xiii] The color and symbol are arbitrary of course, but standard representations enhance readability and give the same type of artifact consistency across projects giving a type of “human resource” re-usability. After all if a consistent symbol is always used to represent the same type of thing less re-learning, is required. This also a principle of good data display, always use the same color to represent the same thing.
[xvi] As a comment I would add that it is often when an enterprise attempts to use a strategy to accomplish more than one mission that it loses sight of the original mission of the strategy and adds unnecessary and dangerous ambiguity to that mission.