In this concluding part of the article about 6BI, I will develop its analysis potential further, show how it compares with architecture frameworks, and cover how it can be utilized for traceability back to the enterprise’s mission statements in order to lend credibility to business performance management (BPM) reporting.
This part was first published in February 2005 under the title “Six Basic Interrogatives – Part 3, 6BI and Business Performance Management ” on the no longer existing Datawarehouse.com website.
Six Basic Interrogatives – Part 3
In two previous articles published in DataWarehouse.com, I described the Six Basic Interrogatives (6BI) Design Framework. In the first article, 6BI was described as an approach to designing databases that support business intelligence applications. In the second article I gave a very simplified example of a scenario and how instances of the business object categories can be identified, as well as introduced my color scheme. In this article I will develop the analysis potential of 6BI further, show how it compares with the Zachman Framework and other architecture frameworks, and cover how 6BI can be utilized for traceability back to the enterprise’s mission statements in order to lend credibility to BPM reporting.
The 6BI Design Framework is a pattern for designing data warehouse dimensions, but it is more than that. It abstracts all dimensions of business intelligence into the six categories of questions that a BI application user might ask. Combinations of questions from these six categories make up the requirements for the models and reports needed by management, analysts, and others within an organization to support decision making. As such, 6BI is an approach that can be used to gather and analyze requirements, and perform gap analysis between “as is” and “to be” models, as well as design the solutions to meet those requirements and close the gaps.
The six categories of the 6BI Design Framework align with the columns of the Zachman Framework for Enterprise Architecture. The Zachman Framework has been widely accepted throughout private industry and has been adopted as a basic building block for major enterprise architecture initiatives within the U.S. Federal Government. Two of these initiatives, in response to the Clinger-Cohen Act of 1996, are the Federal Enterprise Architecture Framework (FEAF) and the Department of Defense Architecture Framework (DoDAF)[1].
The first three rows of the Zachman Framework are Scope, Business Model, and System Model, and represent the Planner’s view, Owner’s view, and Designer’s view of the enterprise respectively[2]. Though originally developed for private sector enterprise information systems, the framework can be (and is) applied to the DoDAF as well, where Scope aligns with Mission Statement, Business Model with Operational Architecture (OA) View, and System Model with Systems Architecture (SA) View, see Figure 1 below. I am going to show how the 6BI Design Framework aligns with both the Zachman Framework and the DoDAF, through the six basic interrogatives. This alignment shows how 6BI can be used to analyze requirements and design solutions as part of both operational architectures and systems architectures that are in synch with an enterprise’s mission.
Figure 1. Zachman Framework and DoDAF alignment.
| View |
Zachman Framework |
DoDAF |
| Planner |
Scope |
Mission Statement |
| Owner |
Business Model |
Operational Architecture View |
| Designer |
System Model |
System Architecture View |
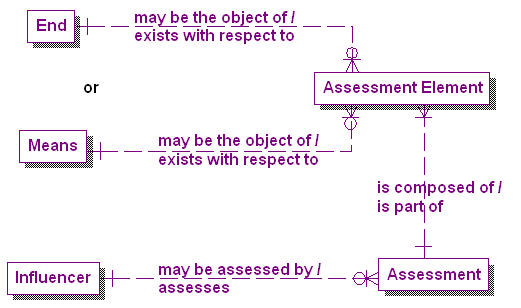
The applicability of 6BI to requirements analysis and solution design is especially true in the area of Business Performance Management (BPM). It is true whether the business is a for-profit enterprise, a not-for-profit organization, or a government agency. The six basic interrogatives and their corresponding business object categories define the context for aligning an enterprise’s Mission Statement with its OA and subsequently with its SA.
Figure 2 shows the six basic interrogatives and the business object categories to which each corresponds. However unlike the Zachman Framework, the order of the interrogatives is significant. It has been my experience that beginning requirements activities by identifying who are the participants (animate and inanimate) that make things happen provides a sound starting point, so I typically begin with the “Who” interrogative. It is not absolutely essential that you identify all of the classes of objects in each category the first time through the framework. The initial pass is a sorting exercise[3] to categorize all of the data elements, classes, and objects to begin to discover common attributes and characteristics among and between them. It is these common elements that enable reuse at a level of abstraction above the purely technical.
Normalization across domains in shared spaces is also enhanced in this way. This means that 6BI gives you a high-level set of classifications in which to group definitions from different systems that describe common object classes. Typically I create a spreadsheet for each business object category (Parties, Products, Activities, etc.), color code[4] them so I can see at a glance which ones I am dealing with at any point, and add or remove rows as I go along. A spreadsheet can generally load most textual data with just a little manipulation and gives you a convenient way to sort and shuffle the entries. This is a working document and usually does not become a permanent artifact of the project.
Figure 2. Six Basic Interrogatives and Business Object Categories.

This is also the point at which you begin to identify the types of numbers, that is the measures and facts, that would most likely be described by the columns (or fields) of the tables you have categorized. For Parties, for example, depending on the business context, you might want to capture and aggregate numbers that derive from activities in which the parties participated, events that are responded to or initiated by the parties, locations where parties operate, or motivators that parties plan or react to. These, of course, are simple two-dimensional analyses but they form the building blocks for more complex queries which make use of more detailed or finer grained levels within each business object category in increasingly complex combinations. Remember the idea here is to provide a starting point for analyzing the source data.
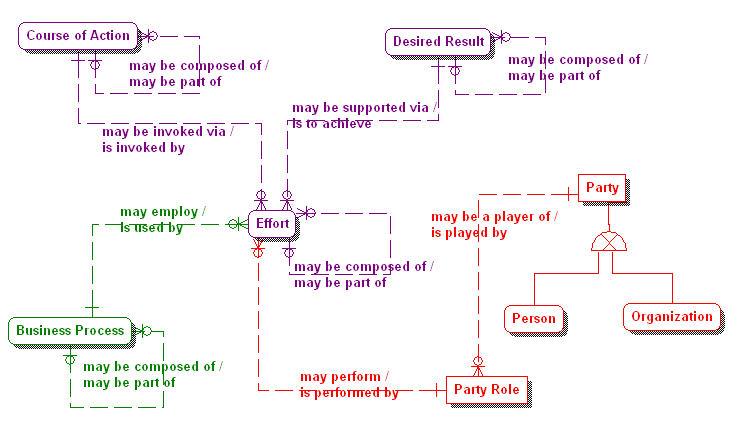
In the 6BI Design Framework, Parties and Products have no direct association with each other. It is only through the other four business object categories (Activities, Events, Locations, and Motivators) that Parties and Products are associated. The left side of Figure 3 shows the relationship of Parties to Activities, Events, Locations and Motivators. The right side shows the relationship of Products to the same four business object categories. This makes sense because only when people engage in activities, exchanging and manipulating things, do frequencies, quantities, monetary amounts, metrics, and other measurements get created.
Figure 3. The indirect association of Parties to Products.

Zachman and DoDAF
Figure 4 is a view of how the corresponding concepts of the Zachman Framework and the DoDAF align with each other and with the six basic interrogatives on which the 6BI Design Framework is based.
Figure 4. Six Basic Interrogatives, Zachman Framework and DoDAF.
| Basic Interrogative |
Zachman Framework |
DoDAF |
| Who produces the data we are going to use to measure performance? |
Business Model –Organizational Units and Work Products |
Operational Architecture –Roles and their Means to Perform Activities |
| System Model – Roles and Deliverables |
Systems Architecture –Systems and Sub-systems |
| What is being manipulated or exchanged to produce the measurable performance? |
Business Model –Business Entities and Relationships |
Operational Architecture –Information Items Input and Output through Activities |
| System Model –Data Entity and Relationships |
Systems Architecture –Data Elements Input and Output through Functions |
| How are the data values that measure performance produced? |
Business Model –Business Processes and their Resources Inputs and Outputs |
Operational Architecture –Node-to-node Information Exchange Activities |
| System Model –Application Functions and User Views of Input and Output |
Systems Architecture –System-to-system Data Transaction Functions |
| When does the activity take place and for how long is the performance measured? |
Business Model –Business Events and Business Cycles |
Operational Architecture –Timing and Sequencing of Activities |
| System Model –System Events and Processing Cycles |
Systems Architecture – Timing and Sequencing of System Events |
| Where does the activity used to measure performance take place? |
Business Model –Business Locations and Linkages |
Operational Architecture –Operational Nodes |
| System Model –System Components and Links |
Systems Architecture – System Nodes |
| Why do we believe the data we are using actually measure performance? |
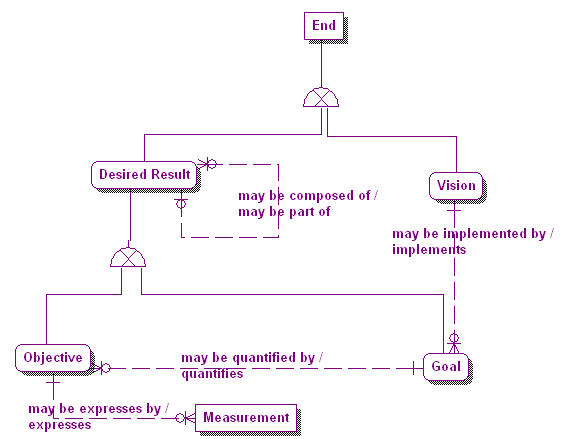
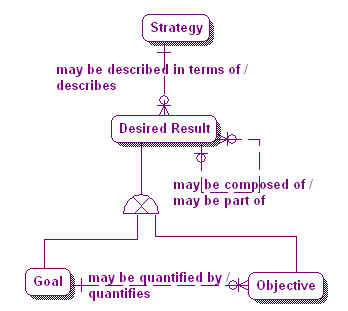
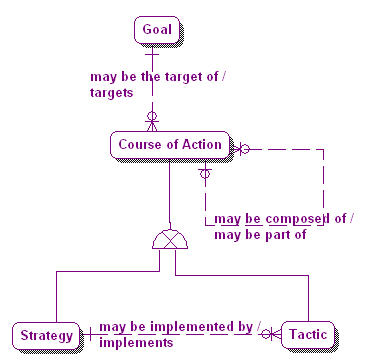
Business Model –Business Objectives and Strategies |
Operational Architecture –Concept of Operations |
| System Model –Structural and Action Assertions |
Systems Architecture – Design Strategy and Rules |
Though rarely are all six interrogatives expressed in a Mission Statement, they are expressed in the OA and the SA. It is at the operational and systems level that BPM report consumers, decision makers at different levels of an organization, need to understand the numbers they are looking at. The types of questions that need to be answered include:
Who is responsible (persons, organizations, systems, etc.) for the numbers? Who are the parties (consumers, payers, providers, sellers, agents, etc.) among whom the exchange is made? Who else (competitors, partners, etc.) participates in this exchange? What is their affinity (participant, observer, etc.) to the market place? Who (government agency, media, etc.) influences the market place in which we exchange products? Who (sellers, producers, managers, others, etc.) need to, or want to, know this information? What is their affiliation (internal party or external party) with me, the first party?
What products (goods or services) are exchanged (bought, sold, produced or consumed) that produce the numbers I am looking at? What type of work effort participated in the exchange? What events influence the exchange? What are the data elements (out of all that are collected and stored) that give me the most relevant information, at the lowest cost, in the least amount of time?
How do the activities (sales, purchases, production runs, case work, intelligence gathering, analytical activity, etc.) engaged in by parties produce the results? How does the exchange take place? What are the functions and activities engaged in? How do activities produce events that influence the numbers? How do events spawn activities that influence the numbers?
When do the events that influence the numbers take place? Which events (contact, proposal, closing, order, delivery, support call, payment, etc.) influence the numbers? Which do not? At what points in time do the influencing events take place? What events take place at given points in time? How long is the time duration of an event? How long between events? What events outside of our control correlate with the numbers? What events cause a particular event? What particular event causes other events?
Where (geographic locations, virtual addresses, etc.) did the events or activities take place? Where is the location of the events that produce the numbers? Where is the placement of the production assets? Where are the participants? What is the spatial relationship between nodes? Between nodes and other dimensions?
Why are particular pieces of information relevant? Why do particular combinations of events and activities produce the results they do? How are ends associated with means? What are the motivators (strategy, tactics, programs, initiatives, rules, etc.) that correlate with the resultant numbers?
Each of the six basic interrogatives addresses an independent category of characteristics about the problem space, yet the categories are inter-related. In fact there are specific associations between each pair of business object categories. These associations can be expressed as a set of one-to-many relationships (see Figure 3) where the “one” side is a specific business object category (e.g. Parties) and the “many” side consists of one or more of the other business object categories that depend on it (i.e. Activities, Events, Locations, and/or Motivators), but not Products. In a 6BI design, Parties and Products are associated only through a linkage with one or more of the other dimensions.
Traceability
6BI is also an approach to designing and building solutions that can be traced back to the characteristics and scope of the problem domain and the mission of the organization. If the use cases and requirements are based on the six basic interrogatives, and the classes, workflows, and events that constitute the design of the component parts of the solution (i.e. the System Architecture) are constructed to address those interrogatives, a clear path from the problem space to the solution space can be described. This path takes guidance from the context of the organization’s scope and mission as also defined in terms of the six basic interrogatives. This can be a basis for validity checking the business use cases used to trace business scenarios.
In other words, the characteristics of the business and the problems that it needs to solve define how the solution needs to be constructed. Each category of the problem is addressed by specific capabilities and components of the solution. Each problem category, and combination of the categories, can be scripted in testing scenarios to exercise those features of the solution designed and constructed to address those specific categories and combinations. Requirements compliance can be traced throughout the lifecycle of a project.
When new requirements need to be met the analyst asks herself, in the discovery activities of the requirements workflow, “Have I accounted for all six of the basic interrogative categories”? If the answer is “yes” she then knows she has a comprehensive and useful framework for going forward and digging deeper for answers and solutions. The possible impact of changes on each business object category can be traced separately or together.
This type of thinking about requirements applies whether the implementation is a custom development or a packaged analytical application. As a matter of fact, 6BI can be the basis of a robust subject matter coverage analysis when evaluating commercial off-the-shelf (COTS) software.
Because business intelligence, especially designing the data stores for data warehouses and other analytical and decision support systems, has progressed over the last decade and a half to where it is a mature discipline, many data architects no longer actually create uniquely designed databases directly from requirements. With the emphasis on design patterns and the availability of domain specific templates and examples, the emphasis is now on gap analysis. Gap analysis is the process of closing the gap between a given design, which can be either an industry standard, a generic model, or built into a product, and the acknowledged data requirements of the problem at hand.
The 6B Design Framework can actually provide a very thorough vehicle to facilitate this gap analysis. 6BI is a way to organize your thinking and help you to know what types of questions to ask in order to “cover all the bases” or make sure no gaps remain in the requirements analysis process. This gap analysis is especially critical in designing databases to support modern business intelligence technologies such as Business Activity Monitoring (BAM) where visibility into business processes and the atomic activities that make them up is critical. It is critical because different sets of events and activities are important to individuals and groups at different levels of an organization. The wider the scope of responsibility of an individual or group, the more aggregated and wider their reporting needs become. In order to aggregate data from more atomic and concrete levels to broader and more abstract levels, the aggregation must take place along one or more dimensions of the data. It is also critical that this visibility into the business processes be as independent of the implementation technology as possible.
The 6BI approach helps to identify these dimensions by grouping them is six distinct categories, each of which is aligned with a type of question an end user might ask about the nature of the information that they need. As questions become more and more detailed and precise within each interrogative category, a 6BI designed system allows the user to drill-down through combinations of dimensions that correspond with the types of questions asked. 6BI identifies the six fundamental business object categories that identify the dimensions of the answers to operational questions about an enterprise, its parties, its products, its activities, its events, its locations, and its motivators.
References
“A framework for information systems architecture” by John Zachman, IBM Systems Journal, Vol 26, No 3, 1987
“Zachman Framework Extensions: An Update” and “Rules for the Zachman Framework Architecture”, Database Newsletter, Vol 19, No. 4, July/August 1991
“DoD Architecture Framework Version 1.0”, U.S. Department of Defense Architecture Framework Working Group, 9 February 2004
[1] I like to think of this object sorting process as analogous to the Sorting Hat process that each first year student at the Hogwarts School of Witchcraft and Wizardry must go through in the Harry Potter books.
[2] The choice of colors is purely arbitrary but I typically use red for “who”, blue for “what”, green for “how”, aqua for “when”, maroon for “where”, and violet for “why”. Proforma ProVision, used for business vision, operations and process modeling, for example, uses a completely different color scheme.
[3] DoDAF was originally called the Command, Control, Communications, Computers, Intelligence, Surveillance, and Reconnaissance (C4ISR) Architecture Framework. It has recently undergone an update and standardization process, in response to user feedback and an executive mandate to provide common standards to improve information sharing, thus the name change.
[4] The additional Zachman Framework rows, Technology Model, Detailed Representation, and Functioning Enterprise, representing the Builder’s view, the Subcontractor’s view, and the Actual System view are not discussed in this article. The Technology Model aligns with the Technical Standards Architecture (TA) View in the DoDAF.